



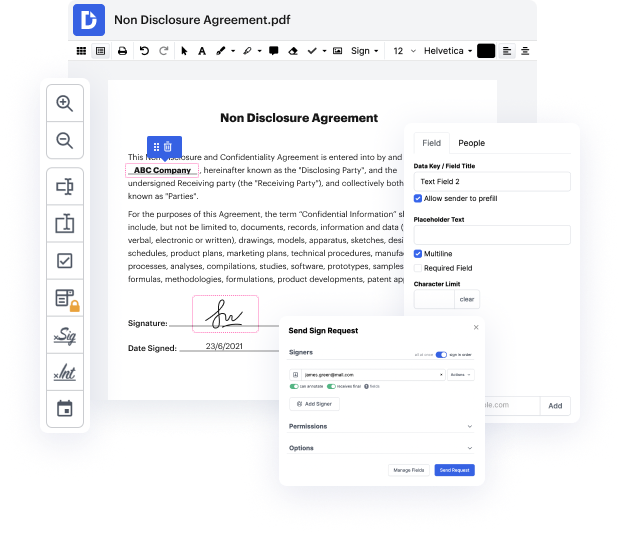
DocHub is an innovative online platform designed to streamline document management, making it easier for users to edit, sign, and distribute their files effectively. With seamless integration with Google Workspace, our editor allows for hassle-free importing, modifying, and signing of documents, ensuring a smooth workflow. Whether you're unlocking a PDF or extracting specific pages, DocHub empowers you to handle your documents precisely how you need, all for free.
Start using DocHub today to effortlessly manage your PDFs and enhance your document workflow!
In today's video tutorial, the focus is on extracting information from PDF files using Python. The goal is to find a solution using one simple library to handle tables, images, and text extraction. However, it is more efficient to use different libraries for specific tasks like extracting images, text, and tables from PDF files. The video will cover three sections, each demonstrating the use of a different Python package to perform various operations on PDF files. If you are working on a large PDF parsing project, this tutorial will guide you through the process.

At DocHub, your data security is our priority. We follow HIPAA, SOC2, GDPR, and other standards, so you can work on your documents with confidence.
Learn more