



There are many document editing tools on the market, but only a few are suitable for all file formats. Some tools are, on the contrary, versatile yet burdensome to work with. DocHub provides the answer to these challenges with its cloud-based editor. It offers robust functionalities that enable you to complete your document management tasks efficiently. If you need to quickly Revise URL in Csv, DocHub is the ideal option for you!
Our process is very straightforward: you upload your Csv file to our editor → it automatically transforms it to an editable format → you apply all necessary changes and professionally update it. You only need a few minutes to get your paperwork ready.
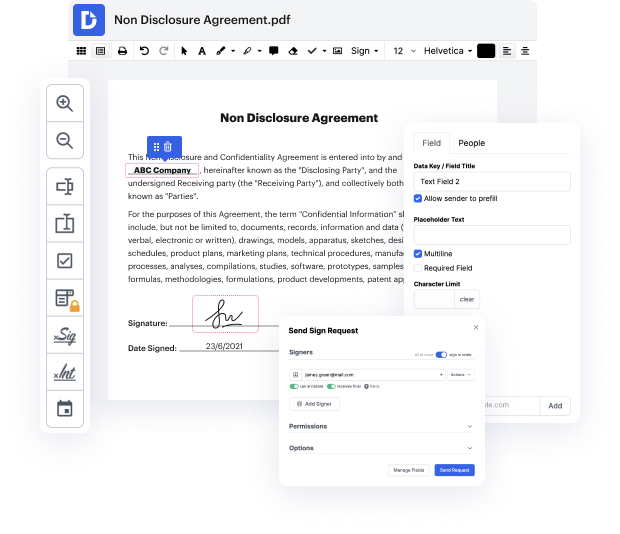
As soon as all alterations are applied, you can transform your paperwork into a reusable template. You only need to go to our editor’s left-side Menu and click on Actions → Convert to Template. You’ll find your paperwork stored in a separate folder in your Dashboard, saving you time the next time you need the same template. Try out DocHub today!
hello everybody so as you can see today we are going to scrape a list of urls from a csv and my subscriber wants to extract the text from all of the pages from all of the sites so he says all data hes actually after all of the text how can i extract all the pages and sub pages from the list of urls in the csv ive found a method but that is only working for a home page can anyone recode and tell me how to extract full data from a website as we cant use xpath for each url i actually provided him with this originally and um with beautiful soup it worked fine not a problem the issue was was he was wanting the text from all of the pages and not just the first page so what ive done instead is other thing cannot actually come up with another idea so if youd like to see that um this is the list of urls so i dont want to show them too closely to sort of give the game away but um weve got uh 469 urls um ive actually been a bit crafty and used vim to strip of

At DocHub, your data security is our priority. We follow HIPAA, SOC2, GDPR, and other standards, so you can work on your documents with confidence.
Learn more