



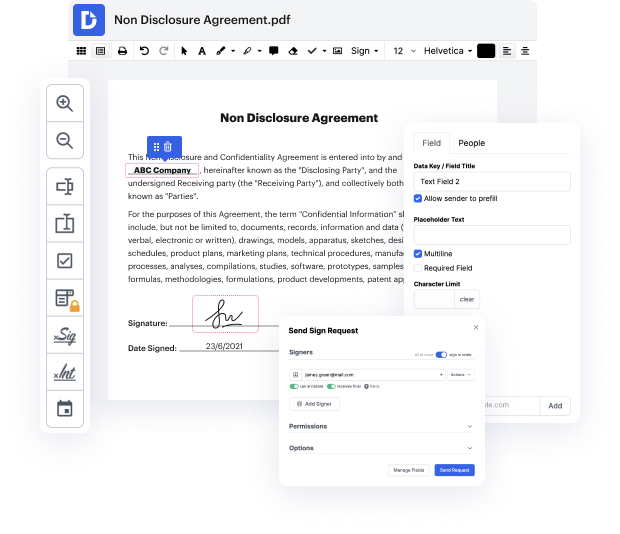
Searching for a specialized tool that deals with particular formats can be time-consuming. Despite the vast number of online editors available, not all of them are suitable for Image format, and definitely not all allow you to make modifications to your files. To make matters worse, not all of them give you the security you need to protect your devices and documentation. DocHub is an excellent solution to these challenges.
DocHub is a popular online solution that covers all of your document editing needs and safeguards your work with bank-level data protection. It works with various formats, such as Image, and helps you modify such documents quickly and easily with a rich and user-friendly interface. Our tool complies with crucial security regulations, like GDPR, CCPA, PCI DSS, and Google Security Assessment, and keeps enhancing its compliance to guarantee the best user experience. With everything it provides, DocHub is the most trustworthy way to Revise type in Image file and manage all of your individual and business documentation, no matter how sensitive it is.
When you complete all of your modifications, you can set a password on your updated Image to make sure that only authorized recipients can open it. You can also save your paperwork with a detailed Audit Trail to check who made what changes and at what time. Choose DocHub for any documentation that you need to edit safely and securely. Sign up now!
Seven years ago, back in 2015, one major development in AI research was automated image captioning. Machine learning algorithms could already label objects in images, and now they learned to put those labels into natural language descriptions. And it made one group of researchers curious. What if you flipped that process around? We could do image to text. Why not try doing text to images and see how it works? It was a more difficult task.They didnt want to retrieve existing images the way google search does. They wanted to generate entirely novel scenes that didnt happen in the real world. So they asked their computer model for something it would have never seen before. Like all the school buses youve seen are yellow. But if you write the red or green school bus would it actually try to generate something green? And it did that. It was a 32 by 32 tiny image. And then all you could see is like a blob of something on top of something. They tried some other prompts lik

At DocHub, your data security is our priority. We follow HIPAA, SOC2, GDPR, and other standards, so you can work on your documents with confidence.
Learn more