



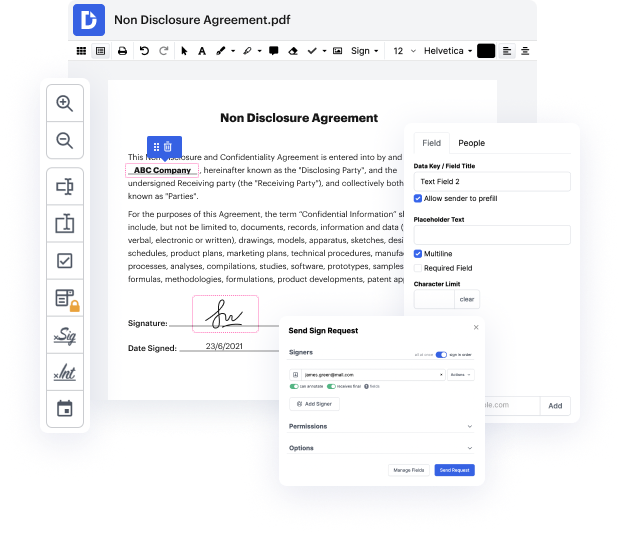
La generación y aprobación de documentos son una prioridad fundamental para cada empresa. Ya sea trabajando con grandes volúmenes de documentos o un contrato específico, debes mantenerte en la cima de tu productividad. Elegir una plataforma en línea perfecta que aborde tus obstáculos más frecuentes en la generación y aprobación de registros puede resultar en bastante trabajo. Numerosas plataformas en línea te ofrecen solo una lista restringida de capacidades de edición y firma electrónica, algunas de las cuales pueden ser útiles para manejar el formato pdf. Una plataforma que maneje cualquier formato y tarea sería una elección excepcional al seleccionar una aplicación.
Lleva la gestión y generación de archivos a un nivel diferente de simplicidad y excelencia sin elegir una interfaz de programa difícil o opciones de suscripción costosas. DocHub te ofrece herramientas y características para manejar eficientemente todos los tipos de archivos, incluyendo pdf, y ejecutar tareas de cualquier complejidad. Edita, gestiona y crea formularios rellenables reutilizables sin esfuerzo. Obtén total libertad y flexibilidad para anular datos en pdf en cualquier momento y almacena de forma segura todos tus documentos completos en tu cuenta o en una de las varias plataformas de almacenamiento en la nube integradas posibles.
DocHub ofrece edición sin pérdidas, recolección de firmas y gestión de pdf a niveles profesionales. No necesitas pasar por guías tediosas e invertir incontables horas averiguando la plataforma. Haz que la edición segura de archivos de primer nivel sea un proceso estándar para tus flujos de trabajo diarios.
¿Qué está pasando, chicos? Bienvenidos de nuevo. En el video de hoy vamos a aprender cómo extraer información de archivos pdf en python, así que vamos a entrar en materia. [Música] Muy bien, así que al preparar el código para este video, quería encontrar una solución donde pudiera usar solo una simple biblioteca de python para trabajar con archivos pdf, para extraer tablas, para extraer imágenes, para extraer texto, y así sucesivamente, todo con una simple biblioteca. Y aunque creo que es posible hacer todo esto con una de estas bibliotecas, descubrí que es mejor o más fácil usar diferentes bibliotecas para los diferentes casos de uso. Así que si quieres extraer imágenes, hay una biblioteca que lo hace fácil para ti; si quieres extraer texto, hay una biblioteca que lo hace fácil para ti; y si quieres extraer tablas, hay una biblioteca diferente que lo hace fácil para ti. Así que en el video de hoy vamos a hacer tres secciones donde usamos tres paquetes de python diferentes para hacer tres cosas diferentes con archivos pdf. Si estás trabajando en un gran análisis de pdf.

En DocHub, la seguridad de tus datos es nuestra prioridad. Seguimos HIPAA, SOC2, GDPR y otros estándares, para que puedas trabajar en tus documentos con confianza.
Aprende más