



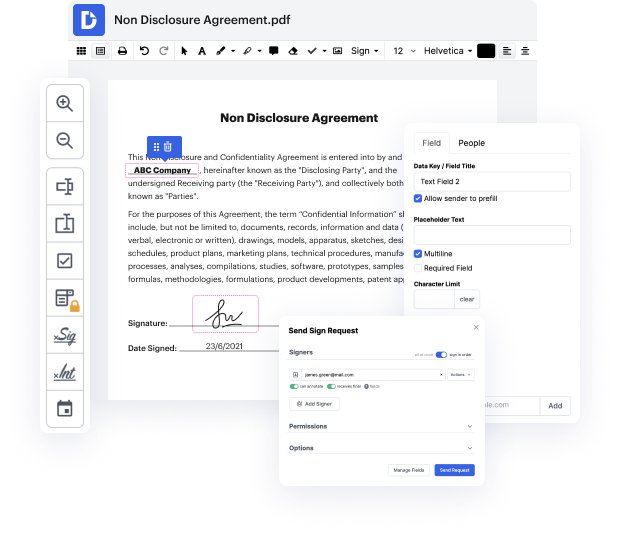
Si editas documentos en varios formatos a diario, la universalidad de la solución de documentos importa mucho. Si tus herramientas solo funcionan para algunos de los formatos populares, puedes encontrarte cambiando entre ventanas de software para insertar índices en DBK y manejar otros formatos de archivo. Si deseas deshacerte de la molestia de la edición de documentos, opta por una solución que pueda gestionar fácilmente cualquier extensión.
Con DocHub, no necesitas concentrarte en nada aparte de la edición real de documentos. No necesitarás malabarear programas para trabajar con varios formatos. Puede ayudarte a modificar tu DBK tan fácilmente como cualquier otra extensión. Crea documentos DBK, edítalos y compártelos en una solución de edición en línea que te ahorra tiempo y mejora tu eficiencia. Todo lo que tienes que hacer es registrar una cuenta en DocHub, lo cual toma solo unos minutos.
No necesitarás convertirte en un multitarea de edición con DocHub. Su conjunto de características es suficiente para la edición rápida de documentos, independientemente del formato que necesites revisar. Comienza registrando una cuenta para ver lo fácil que puede ser la gestión de documentos con una herramienta diseñada específicamente para satisfacer tus necesidades.
Hoy vamos a ejecutar consultas SQL contra a una tabla que contiene diez MIL registros. {{ Risa maníaca }} {{ Llamada telefónica }} ¿Qué pasa? Estoy en medio de un video. ¿No me digas? ¿TODO en RAM? Bueno, está bien. Hoy vamos a ejecutar consultas SQL contra a una tabla que contiene un .. Cien .. MILLONES de registros. {{ Risa maníaca }} Pero no te preocupes. Al usar índices, podemos acelerar rápidamente las consultas para que no tengas que experimentar el fenómeno conocido como aburrimiento. Trabajaremos con una sola tabla llamada persona que contiene 100 MILLONES de personas generadas aleatoriamente. La primera fila es una clave primaria auto-generada llamada personid. Las otras columnas son firstname, lastname y birthday. Para crear esta tabla, generamos aleatoriamente nombres usando los 1000 nombres femeninos, masculinos y apellidos más populares en los Estados Unidos. No ponderamos los nombres por frecuencia al generar nuestra muestra aleatoria. Los conjuntos de datos y el código de Python utilizado para generar los nombres aleatorios están disponibles.
