



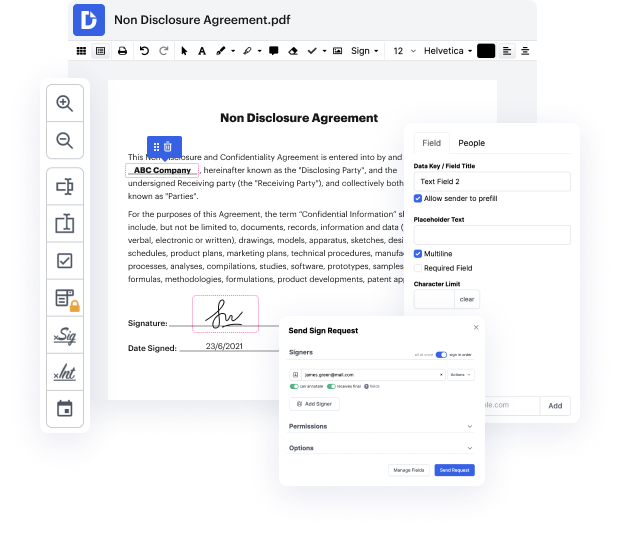
La generación y aprobación de documentos son una prioridad fundamental para cada empresa. Ya sea trabajando con grandes volúmenes de documentos o un acuerdo específico, necesitas mantenerte en la cima de tu eficiencia. Elegir una excelente plataforma en línea que aborde tus problemas más típicos de creación y aprobación de documentos puede resultar en mucho trabajo. Numerosas plataformas en línea te ofrecen solo un conjunto mínimo de funciones de edición y eFirma, algunas de las cuales podrían ser útiles para manejar el formato de documentos. Una plataforma que maneje cualquier formato y tarea sería una elección excepcional al elegir software.
Lleva la gestión y creación de documentos a otro nivel de eficiencia y excelencia sin elegir una interfaz de usuario incómoda o un plan de suscripción costoso. DocHub te ofrece herramientas y características para manejar con éxito todos los tipos de documentos, incluyendo documentos, y realizar tareas de cualquier complejidad. Modifica, organiza y crea formularios rellenables reutilizables sin esfuerzo. Obtén completa libertad y flexibilidad para limpiar el token en el documento en cualquier momento y almacena de forma segura todos tus documentos completos dentro de tu perfil de usuario o en una de las muchas plataformas de almacenamiento en la nube integradas posibles.
DocHub ofrece edición sin pérdida, recolección de eFirma y gestión de documentos a un nivel profesional. No necesitas pasar por tutoriales tediosos y gastar horas y horas descubriendo el software. Haz que la edición segura de documentos de primer nivel sea una práctica habitual para los flujos de trabajo diarios.
En el video de hoy, vamos a hablar sobre la tokenización en spaCy. También podemos hacer tokenización en NLTK. Hemos discutido los pros y los contras entre estas dos bibliotecas y, decidimos que usaríamos spaCy por las razones que mencioné en el último video. Y si recuerdas nuestro video sobre la tubería de NLP, teníamos este uh este paso llamado pre-procesamiento. Así que en toda esta tubería de NLP, vamos a comenzar con el paso de pre-procesamiento. La adquisición de datos y el paso de extracción y limpieza de texto es algo que quizás podamos revisar más tarde, tal vez en el proyecto de NLP de extremo a extremo. Pero en el pre-procesamiento lo que aprendimos fue que hay un paso llamado tokenización de oraciones, cuando tienes un párrafo de texto. Primero lo separas en oraciones y luego cada oración la divides en las palabras. Así que eso se llama tokenización de palabras. Así que vamos a ver cómo puedes hacer ambas cosas en la biblioteca spaCy. Además, había stemming, lematización, cubriremos stemming, lematización más tarde

En DocHub, la seguridad de tus datos es nuestra prioridad. Seguimos HIPAA, SOC2, GDPR y otros estándares, para que puedas trabajar en tus documentos con confianza.
Aprende más