



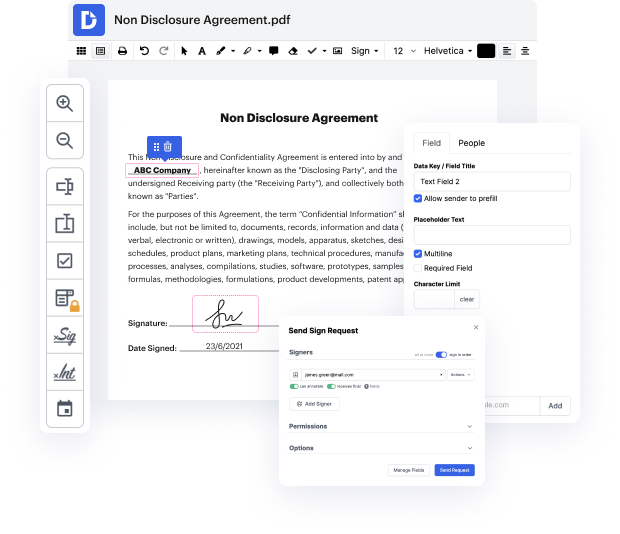
Trabajar con documentos como catálogos puede parecer un desafío, especialmente si es la primera vez que trabajas con este tipo. A veces, una pequeña modificación puede crear un gran dolor de cabeza cuando no sabes cómo trabajar con el formato y evitar hacer un caos del proceso. Cuando se te asigna limpiar datos en un catálogo, siempre puedes hacer uso de un software de edición de imágenes. Otras personas pueden optar por un editor de texto convencional, pero se quedan atascadas cuando se les pide reformatear. Con DocHub, sin embargo, manejar un catálogo no es más difícil que editar un archivo en cualquier otro formato.
Prueba DocHub para una edición de documentos rápida y eficiente, independientemente del formato del documento que tengas en tus manos o del tipo de documento que necesites corregir. Esta solución de software es en línea, accesible desde cualquier navegador con una conexión a internet estable. Modifica tu catálogo justo cuando lo abras. Hemos diseñado la interfaz para asegurar que incluso los usuarios sin experiencia previa puedan hacer fácilmente todo lo que necesiten. Simplifica la edición de tus documentos con una única solución elegante para cualquier tipo de documento.
Tratar con diferentes tipos de documentos no debe sentirse como ciencia espacial. Para optimizar tu tiempo de edición de documentos, necesitas una solución rápida como DocHub. Maneja más con todas nuestras herramientas al alcance de tu mano.
Este video es parte del certificado de Google en Análisis de Datos, que ofrece habilidades listas para el trabajo para una carrera en análisis de datos. El costo anual de la mala calidad de los datos en EE. UU. es de 3.1 billones de dólares, siendo el error humano la causa principal. La precisión de los datos es crucial para que las empresas eviten pérdidas financieras.

En DocHub, la seguridad de tus datos es nuestra prioridad. Seguimos HIPAA, SOC2, GDPR y otros estándares, para que puedas trabajar en tus documentos con confianza.
Aprende más