



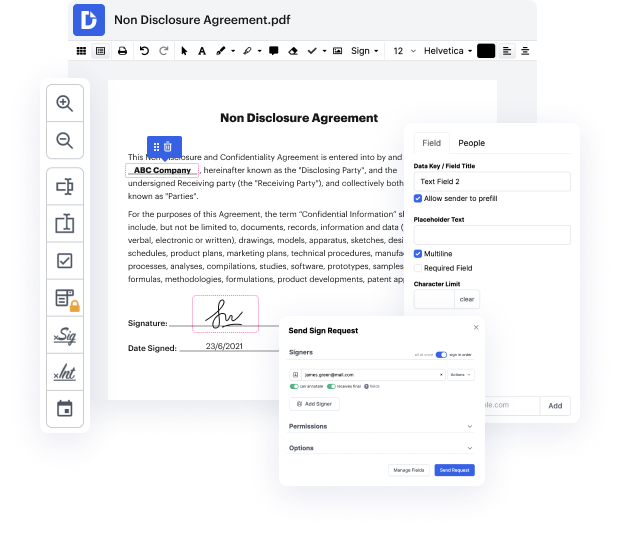
Whether you are already used to working with jpeg or handling this format the very first time, editing it should not seem like a challenge. Different formats might require particular applications to open and edit them effectively. Yet, if you have to quickly void number in jpeg as a part of your usual process, it is advisable to get a document multitool that allows for all types of such operations without extra effort.
Try DocHub for streamlined editing of jpeg and other document formats. Our platform provides easy papers processing regardless of how much or little prior experience you have. With all tools you have to work in any format, you will not need to switch between editing windows when working with every one of your papers. Easily create, edit, annotate and share your documents to save time on minor editing tasks. You’ll just need to sign up a new DocHub account, and you can begin your work immediately.
See an improvement in document management efficiency with DocHub’s simple feature set. Edit any document quickly and easily, regardless of its format. Enjoy all the benefits that come from our platform’s efficiency and convenience.
welcome back this is episode four of everything you need to know about JPEG last episode we covered writing pixel arrays two bitmap files this episode we will begin the journey of creating such a pixel array from the Huffman coded bit stream that we already read out of the jpg file before we get into Huffman decoding lets first talk a little longer about Huffman coding how to compress data using the Huffman coding system then well come back to Huffman decoding where we decode the bitstream into a giant MCU array in episode 2 I fully explained what the symbols are what they mean and how theyre used but Ive always beat around the bush about what Huffman codes are and how theyre used now we are finally going to get into all the detail about what exactly a Huffman code is first lets remind ourselves what the purpose of using Huffman coding is the purpose is to take the original data and compress it based on the frequency of certain values in the data how often certain values occur i

At DocHub, your data security is our priority. We follow HIPAA, SOC2, GDPR, and other standards, so you can work on your documents with confidence.
Learn more