



Not all formats, including csv, are developed to be easily edited. Even though many capabilities will let us tweak all file formats, no one has yet created an actual all-size-fits-all solution.
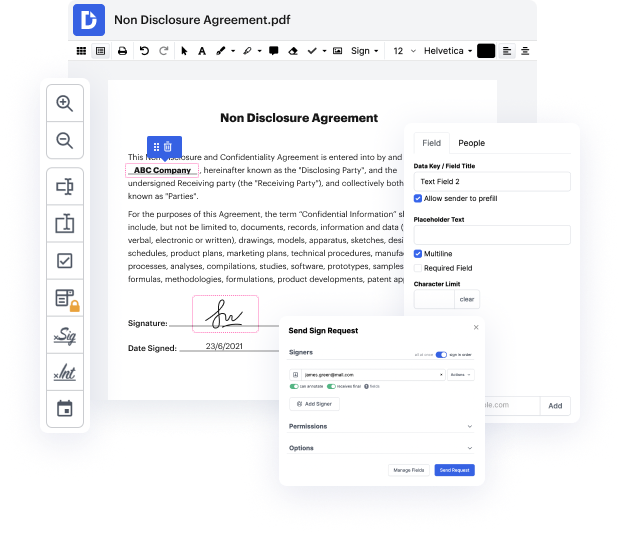
DocHub gives a simple and streamlined solution for editing, managing, and storing paperwork in the most widely used formats. You don't have to be a technology-savvy person to undo name in csv or make other modifications. DocHub is robust enough to make the process simple for everyone.
Our feature allows you to modify and tweak paperwork, send data back and forth, generate interactive documents for data gathering, encrypt and shield forms, and set up eSignature workflows. In addition, you can also create templates from paperwork you utilize on a regular basis.
You’ll locate a great deal of other functionality inside DocHub, such as integrations that allow you to link your csv file to a variety productivity programs.
DocHub is an intuitive, cost-effective way to manage paperwork and streamline workflows. It provides a wide range of features, from generation to editing, eSignature professional services, and web form developing. The application can export your documents in many formats while maintaining highest security and adhering to the greatest data security criteria.
Give DocHub a go and see just how simple your editing transaction can be.
itamp;#39;s day 74 of learning python in todayamp;#39;s video Iamp;#39;m going to show you how to remove duplicate rows in a CSV file using pandas this is the data set Iamp;#39;m going to use for this example as you can see here thereamp;#39;s three rows that contain Mario with h30 what we want to do is actually remove these from the data set so we only get Mario Luigi and Wario one time with that said the first thing we need to do is import pandas I imported pandas as PD next we need to load the CSV file I did this by setting DF equal to pd.read CSV and in the parentheses I put the file name which in this case is duplicates.csv to get rid of the duplicate rows Iamp;#39;m going to create a new variable called unique DF and set that equal to df.drop duplicates with open and close parentheses now if I print unique DF and run the code you see we get three rows Mario h30 Luigi age 28 and Wario h26 so it removed the extra two rows of Mario h30 if you want to learn more python like sub
