



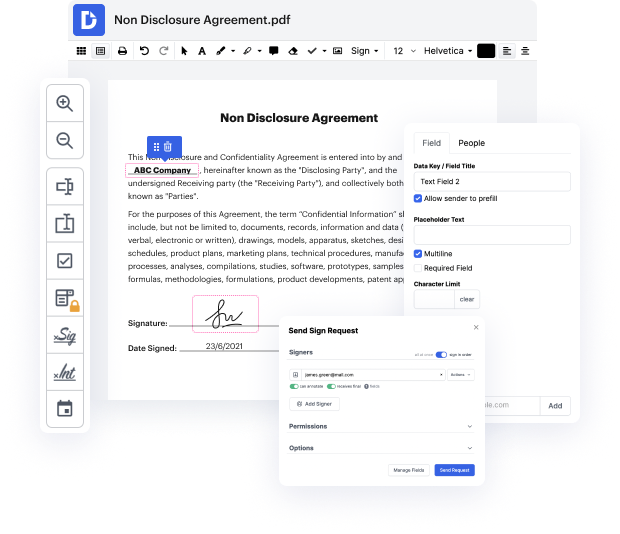
DocHub is an all-in-one PDF editor that lets you take out token in scii, and much more. You can highlight, blackout, or remove document components, add text and images where you need them, and collect data and signatures. And since it works on any web browser, you won’t need to update your hardware to access its powerful features, saving you money. With DocHub, a web browser is all it takes to process your scii.
Log in to our website and follow these guidelines:
It couldn't be simpler! Improve your document management today with DocHub!
everyone welcome to the new section retrieving information from text data in this section we will detect s and sentences using Java and open NLP will then retrieve lemma part of speech and recognized named entities from s using stanford core NLP will also measure text similarity with cosine similarity measure using Java 8 later on weamp;#39;ll extract topics from text documents using mallet lastly will classify text documents using mallet and whacker letamp;#39;s start with the first video of this section that deals with detecting s using Java one of the most common tasks that a data scientist needs to do using text data is to detect s from it this task is called ization in this video we will use three different techniques that when applied to the same string yield three different results to get started visit this link and go through the documentation on the regular expression pattern supported by the pattern class also see the examples at this link this will give you an idea of the
