



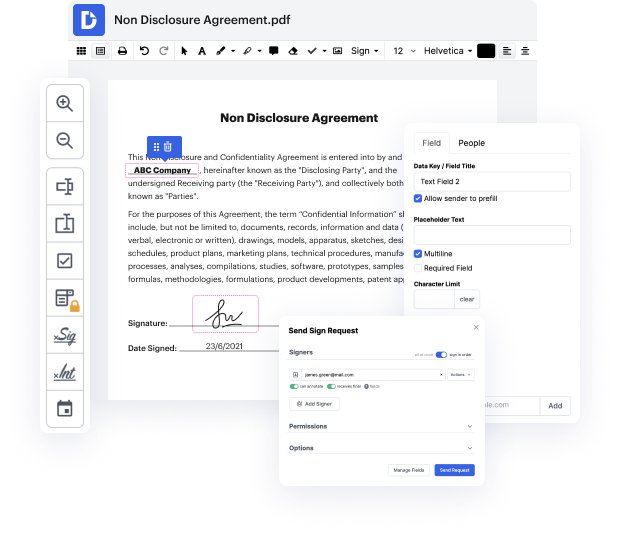
People often need to negate caption in image when working with forms. Unfortunately, few applications offer the options you need to accomplish this task. To do something like this usually involves switching between a couple of software packages, which take time and effort. Luckily, there is a solution that works for almost any job: DocHub.
DocHub is an appropriately-built PDF editor with a full set of valuable functions in one place. Modifying, approving, and sharing paperwork gets straightforward with our online solution, which you can use from any online device.
By following these five easy steps, you'll have your modified image quickly. The intuitive interface makes the process quick and effective - stopping switching between windows. Start using DocHub now!
In this video, we will create a machine learning model that can describe images using words, also known as image captioning. So, till the end, you will create an interface like this in which generating captions is as easy as clicking on this button, choosing whatever image you like, and getting the captions back. The concept of image captioning is fairly simple. You take an image and try to generate a caption that matches the gist of that image as closely as possible. Like here, the caption of this image is amp;quot;Baseball game in large stadium with ball flying toward batteramp;quot;. This summarises the entire meaning of the image in a single sentence. As humans, we have no trouble doing this, but back in 2015, image captioning was considered one of the most difficult tasks in machine learning since it lies at the intersection between NLP and computer vision. They both have to work in coordination to make image captioning possible. Then the attention mechanism came to the rescue,
