



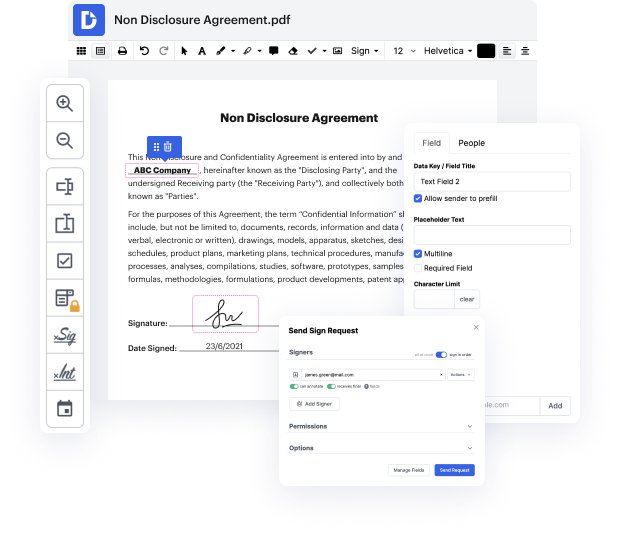
It is usually difficult to get a platform that can cover all of your business needs or will provide you with suitable instruments to manage document generation and approval. Picking an application or platform that includes crucial document generation instruments that streamline any process you have in mind is critical. Although the most popular file format to use is PDF, you need a comprehensive software to manage any available file format, such as INFO.
DocHub ensures that all of your document generation requirements are covered. Revise, eSign, turn and merge your pages according to your requirements with a mouse click. Work with all formats, such as INFO, efficiently and quickly. Regardless of what file format you begin dealing with, it is simple to transform it into a needed file format. Save tons of time requesting or looking for the appropriate file format.
With DocHub, you don’t require extra time to get used to our interface and editing procedure. DocHub is undoubtedly an intuitive and user-friendly software for anyone, even all those with no tech background. Onboard your team and departments and change document administration for your organization forever. fix label in INFO, generate fillable forms, eSign your documents, and have things completed with DocHub.
Benefit from DocHub’s extensive feature list and rapidly work with any document in any file format, such as INFO. Save time cobbling together third-party platforms and stay with an all-in-one software to further improve your day-to-day operations. Begin your cost-free DocHub trial subscription today.
in this video well see how you can use model to find and fix labeling errors first off your model is only as good as your training data and a great way to boost model performance is to find and fix the labeling mistakes in your training data its more common than you think for labels to contain noise and errors even the most canonical ml data sets out there have quite a lot of labeling mistakes why is that because labels are generated by humans and humans can sometimes make mistakes some labels are also inherently ambiguous and lastly its impossible to review all of your labels manually or to have them checked by a panel of labelers so the bottom line is that this labeling noise can undermine your model a key question for ML and labeling teams is where are my labels wrong and where is it impacting my model you can use your trained model as a guide to find labeling mistakes so heres a systematic process that weve seen success with over and over again Step One is looking for assets
