



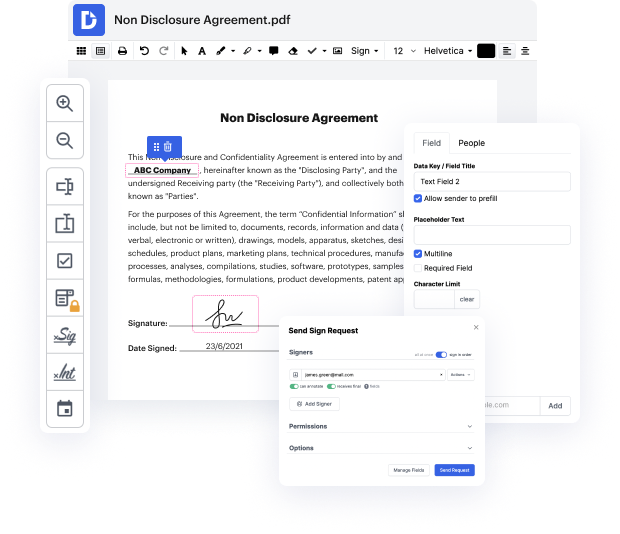
Having comprehensive control of your papers at any moment is important to alleviate your everyday tasks and boost your productivity. Achieve any objective with DocHub features for document management and practical PDF file editing. Gain access, modify and save and integrate your workflows along with other secure cloud storage services.
DocHub gives you lossless editing, the chance to work with any format, and securely eSign papers without searching for a third-party eSignature option. Get the most of the document managing solutions in one place. Check out all DocHub functions right now with your free account.
In this tutorial, you will learn how to extract text from a PDF file in under 60 seconds using the Pi PDF library. First, install the library with the command `pip install PyPDF2`. After importing the package using `from PyPDF2 import PdfReader`, create a PDF reader object by specifying the file path. Next, create a dictionary called `page_content` to store the content of each page. Utilize a loop with `enumerate` to iterate through the PDF pages, storing the page number as the key (index + 1) and the extracted text as the value using `pdf_page.extract_text()`. Finally, print the `page_content` dictionary to display the extracted text.
