



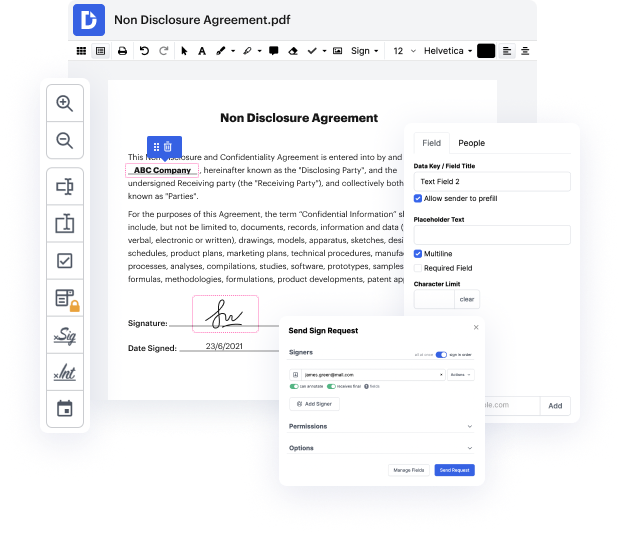
Having complete control of your papers at any time is essential to alleviate your day-to-day tasks and improve your efficiency. Achieve any goal with DocHub tools for papers management and practical PDF file editing. Access, adjust and save and incorporate your workflows with other safe cloud storage services.
DocHub offers you lossless editing, the possibility to work with any formatting, and safely eSign papers without having looking for a third-party eSignature option. Obtain the most of your document managing solutions in one place. Check out all DocHub capabilities right now with your free of charge profile.
what is going on guys welcome back in todays video were going to learn how to extract information from pdf files in python so lets get right into it [Music] all right so when preparing the code for this video i wanted to find a solution where i can use just one simple python library to work with pdf files to extract tables to extract images to extract text and so on all with one simple library and even though i think its possible to do all this with one of these libraries i figured out that its better or easier to use different libraries for the different use cases so if you want to extract images theres a library that makes it easy for you if you want to extract text theres a library that makes it easy for you and if you want to extract tables there is a different library that makes it easy for you so were going to do in todays video three sections where we use three different python packages to do three different things with pdf files if youre working on a huge pdf parsing
