



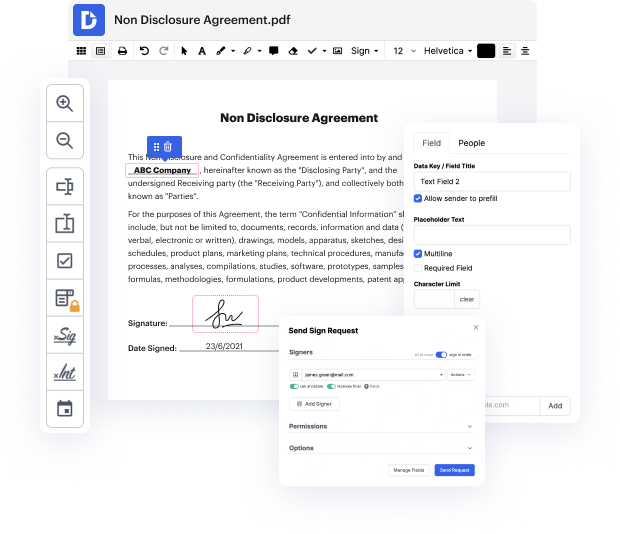
There are many document editing solutions on the market, but only some are suitable for all file formats. Some tools are, on the other hand, versatile yet burdensome to use. DocHub provides the answer to these hassles with its cloud-based editor. It offers robust capabilities that allow you to complete your document management tasks effectively. If you need to quickly Embed phrase in NBP, DocHub is the ideal choice for you!
Our process is very straightforward: you import your NBP file to our editor → it instantly transforms it to an editable format → you make all essential adjustments and professionally update it. You only need a couple of moments to get your paperwork ready.
When all modifications are applied, you can transform your paperwork into a multi-usable template. You only need to go to our editor’s left-side Menu and click on Actions → Convert to Template. You’ll locate your paperwork stored in a separate folder in your Dashboard, saving you time the next time you need the same template. Try DocHub today!
In this NLP playlist we have covered the text representation techniques from label encoding to TF-IDF Today we are going to talk about word embeddings. There are certain limitations of Bag of words and TF-IDF which we have discussed in previous videos, which is the vector size can really be big for bag of words and TF-IDF model. And it may consume lot of compute resources, memory and so on. Lets say you have vocabulary of 200,000 words or 100,000 words each vector for each of the documents would be 100 000 size and that that may be too much and the presentation is sparse meaning in that vector most of the values are 0. So it is not a very efficient presentation. The other problem we saw was that lets say you have 2 words I need help, I need assistance these are similar sentences. You expect that their vector representation should be similar, but since these are TF-IDF and bag of words are count based methods, the vector representation might not be similar. Here you can see see there
