



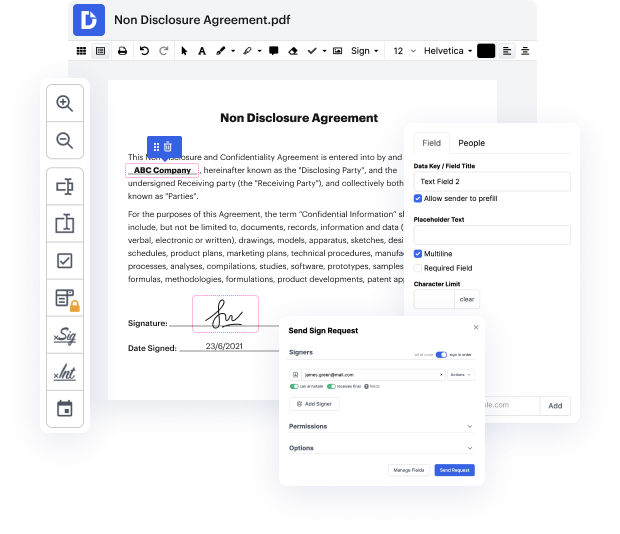
DocHub is an all-in-one PDF editor that allows you to conceal answer in EZW, and much more. You can underline, blackout, or remove paperwork elements, insert text and images where you need them, and collect data and signatures. And because it works on any web browser, you won’t need to update your device to access its powerful tools, saving you money. With DocHub, a web browser is all it takes to process your EZW.
Sign in to our service and follow these instructions:
It couldn't be easier! Improve your document management today with DocHub!
this is joint work of umass amherst and facebook air research in this paper we found precise localizations of objects using bounty boxes for vqa are not necessary ing to the attention maps our model grid features can capture relevant video concepts to correctly answer the question to make great features work instead of training a vanilla fast rca model we use a dilated c5 model with one by one ri puller we use feature maps in the last layer of the backbone as grid features a large resolution of the input image is also critical our grid features work well across different backbones different vqa tasks different vqa models and even image captioning tasks particularly we achieved the r accuracy on vqa2 with great features as we skip region related computations we get a 40 times speed up during the inference stage with grid features moreover we can do entrant training for vqa and get better accuracy this is not trivial for region features as funding box annotations are really not available
