



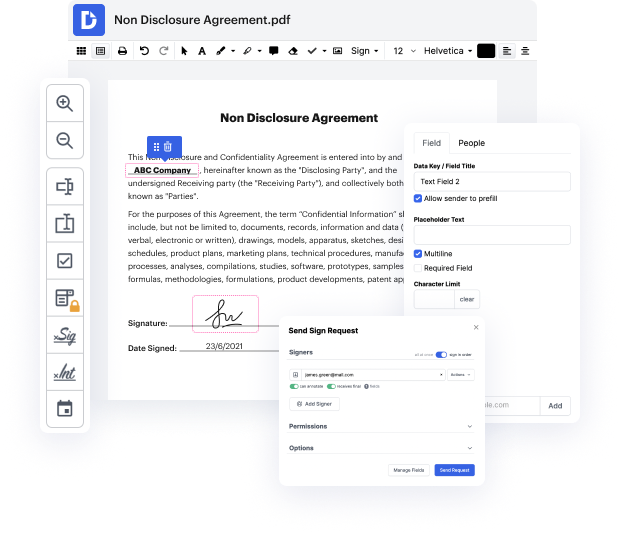
scii may not always be the simplest with which to work. Even though many editing tools are available on the market, not all offer a easy solution. We created DocHub to make editing easy, no matter the document format. With DocHub, you can quickly and easily clear up URL in scii. Additionally, DocHub offers a variety of additional tools such as document creation, automation and management, field-compliant eSignature tools, and integrations.
DocHub also lets you save time by creating document templates from documents that you use frequently. Additionally, you can make the most of our a wide range of integrations that enable you to connect our editor to your most utilized applications easily. Such a solution makes it fast and simple to deal with your documents without any delays.
DocHub is a handy feature for individual and corporate use. Not only does it offer a all-purpose set of features for document generation and editing, and eSignature implementation, but it also has a variety of tools that prove useful for creating complex and straightforward workflows. Anything uploaded to our editor is stored risk-free in accordance with leading field standards that safeguard users' data.
Make DocHub your go-to choice and simplify your document-based workflows easily!
today weamp;#39;ll be discussing the URL submitter this tool gives you the ability to control our web crawler to crawl the domains or URLs you want us to this is helpful for two reasons to ensure Majestic reports on links you have received or successfully removed and as part of an ongoing audit of your site the URL submitter is included in all paid plans and is found in the tools menu you can submit up to 1 million URLs using the file upload function you can copy and paste up to 100 URLs at a time in the web form or you can import a list of URLs from your bucket first 100 URLs you submit are included in your subscription with additional crawl requests costing 50 analysis units per URL the URL submitter is a request to crawl a page rather than a promise from us that we will crawl it sometimes we cannot crawl a page because I crawl the respects robots.txt files and the crawl delay protocol
