



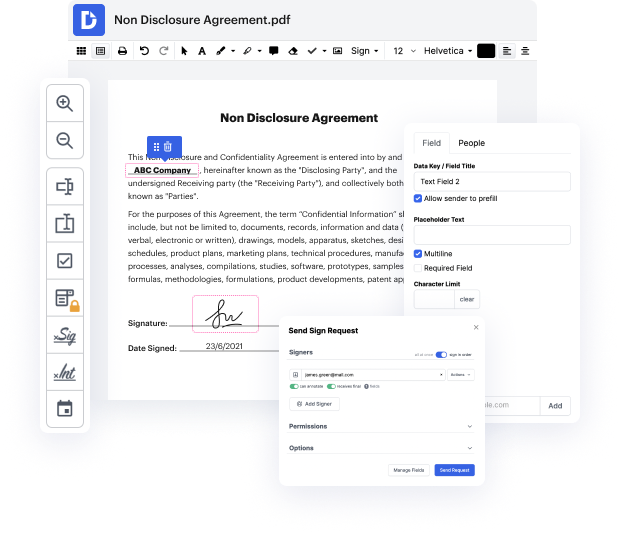
Unusual file formats within your day-to-day document management and editing processes can create instant confusion over how to modify them. You might need more than pre-installed computer software for efficient and fast document editing. If you want to clean word in WRD or make any other simple alternation in your document, choose a document editor that has the features for you to work with ease. To deal with all the formats, such as WRD, opting for an editor that actually works properly with all kinds of files will be your best option.
Try DocHub for efficient document management, irrespective of your document’s format. It offers powerful online editing tools that streamline your document management process. It is easy to create, edit, annotate, and share any file, as all you need to gain access these features is an internet connection and an active DocHub profile. Just one document solution is all you need. Don’t lose time switching between various programs for different files.
Enjoy the efficiency of working with an instrument designed specifically to streamline document processing. See how straightforward it really is to revise any document, even when it is the first time you have worked with its format. Sign up an account now and enhance your whole working process.
The video tutorial discusses the importance of proper text analysis, starting with tokenization to identify potential issues in the text. After tokenization, the focus shifts to creating better input text for more accurate analysis. The tutorial introduces a dataset of Russian troll tweets from the 2016 US election cycle, including metadata such as followers and account type for analysis. This dataset is ideal for various tasks like topic modeling and classification due to the abundance of potentially misleading information in tweets.
