



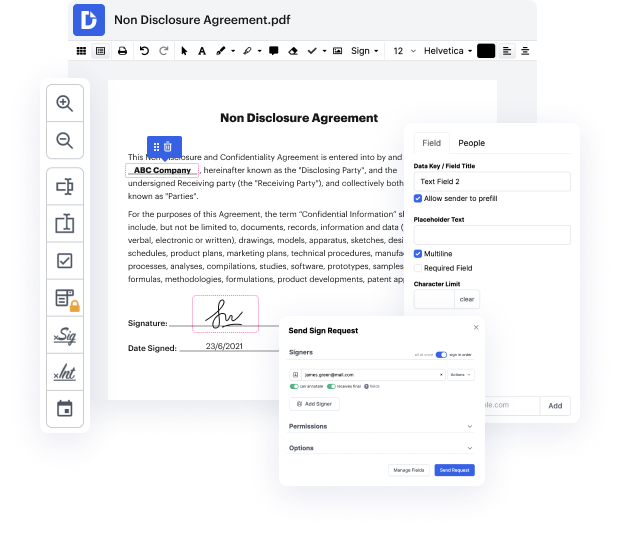
Document generation and approval are a core priority of each company. Whether working with large bulks of documents or a certain agreement, you need to stay at the top of your efficiency. Choosing a excellent online platform that tackles your most typical record creation and approval problems may result in a lot of work. Numerous online platforms offer you just a minimal set of editing and eSignature functions, some of which could possibly be beneficial to deal with doc formatting. A platform that handles any formatting and task would be a exceptional choice when choosing program.
Get document management and creation to another level of efficiency and excellence without picking an awkward user interface or high-priced subscription plan. DocHub offers you tools and features to deal successfully with all of document types, including doc, and carry out tasks of any complexity. Modify, arrange, and create reusable fillable forms without effort. Get complete freedom and flexibility to clean token in doc at any moment and securely store all your complete documents within your user profile or one of many possible integrated cloud storage platforms.
DocHub offers loss-free editing, eSignaturel collection, and doc management on a expert level. You don’t need to go through tedious tutorials and spend hours and hours finding out the software. Make top-tier secure document editing a typical practice for the daily workflows.
In todays video, we are going to talk about tokenization in spaCy. We can do tokenization in NLTK as well. We have discussed the pros and cons between these two libraries and, we decided well use spaCy for the reasons I mentioned in the last video. And if you remember our NLP pipeline video, we had this uh this step called pre-processing. So in this entire NLP pipeline, were going to begin with the pre-processing step. The data acquisition and text extraction and cleanup step is something we can maybe take a look at later, maybe in the end-to-end NLP project. But in pre-processing what we learned was, there is a step called sentence tokenization, when you you have a paragraph of text. You first separate it out in sentences and then each sentence you split it out in the into the words. So thats called word tokenization. So we are going to see how you can do both of these things in spaCy library. Also, there was stemming, lemmetization well cover stemming, lemmetization in the late

At DocHub, your data security is our priority. We follow HIPAA, SOC2, GDPR, and other standards, so you can work on your documents with confidence.
Learn more