



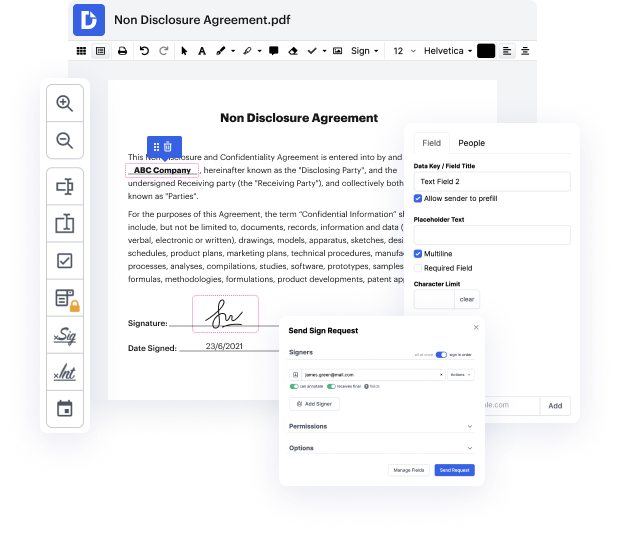
DocHub is an all-in-one PDF editor that lets you blot pagenumber in xml, and much more. You can underline, blackout, or remove paperwork fragments, add text and images where you need them, and collect data and signatures. And since it runs on any web browser, you won’t need to update your software to access its professional capabilities, saving you money. With DocHub, a web browser is all it takes to handle your xml.
Log in to our service and follow these guidelines:
It couldn't be easier! Improve your document management now with DocHub!
thank you welcome back the next step is we need to read the XML file and from that XML file we need to extract the file name size object Etc thatamp;#39;s what we need to extract from the XML file okay so that my step number two read XML file and from that XML file from each XML file we need to extract first one is file name and from size we need to extract the width and height of the image next from object we need to extract the name X-Men x max y Min and Y Max so these are not the information we need to extract from the XML file we know that letamp;#39;s say this is my XML file using this elements we can simply extract those information before that letamp;#39;s see how to load an XML file and from that how we can able to extract this or pass it we will see that all right the first step is let me Define the tree is equal to e t which is my elementary which I already imported from this step now here et.parse and we need to provide letamp;#39;s say for the sake of Si
