



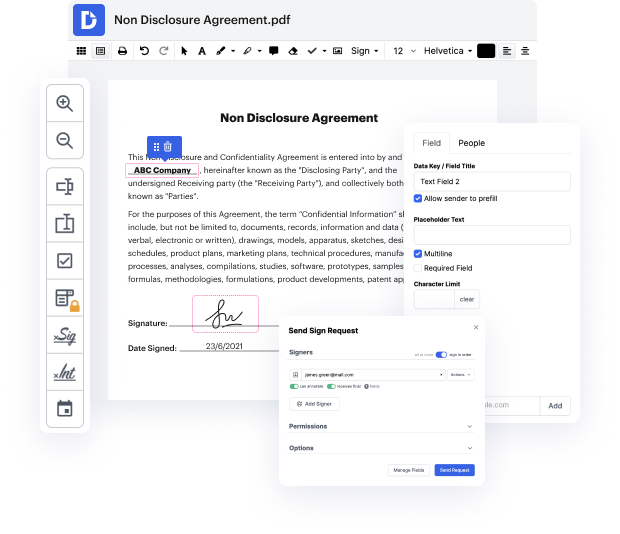
image may not always be the best with which to work. Even though many editing features are out there, not all provide a easy solution. We developed DocHub to make editing straightforward, no matter the document format. With DocHub, you can quickly and easily adapt caption in image. Additionally, DocHub delivers a range of additional tools including form creation, automation and management, industry-compliant eSignature solutions, and integrations.
DocHub also enables you to save effort by producing form templates from paperwork that you use frequently. Additionally, you can take advantage of our numerous integrations that enable you to connect our editor to your most used apps with ease. Such a solution makes it fast and simple to work with your documents without any delays.
DocHub is a helpful feature for individual and corporate use. Not only does it provide a all-purpose set of capabilities for form creation and editing, and eSignature integration, but it also has a range of features that come in handy for creating complex and straightforward workflows. Anything added to our editor is kept secure according to major field criteria that protect users' information.
Make DocHub your go-to option and streamline your form-centered workflows with ease!
In this video, we will create a machine learning model that can describe images using words, also known as image captioning. So, till the end, you will create an interface like this in which generating captions is as easy as clicking on this button, choosing whatever image you like, and getting the captions back. The concept of image captioning is fairly simple. You take an image and try to generate a caption that matches the gist of that image as closely as possible. Like here, the caption of this image is amp;quot;Baseball game in large stadium with ball flying toward batteramp;quot;. This summarises the entire meaning of the image in a single sentence. As humans, we have no trouble doing this, but back in 2015, image captioning was considered one of the most difficult tasks in machine learning since it lies at the intersection between NLP and computer vision. They both have to work in coordination to make image captioning possible. Then the attention mechanism came to the rescue,

At DocHub, your data security is our priority. We follow HIPAA, SOC2, GDPR, and other standards, so you can work on your documents with confidence.
Learn more