



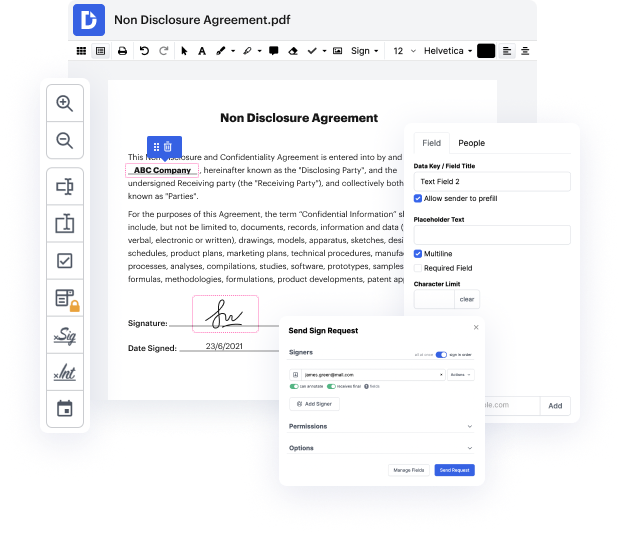
Document generation and approval are a central focus for each company. Whether handling sizeable bulks of files or a particular agreement, you should remain at the top of your efficiency. Getting a perfect online platform that tackles your most typical papers generation and approval difficulties may result in a lot of work. Many online apps offer only a restricted set of editing and eSignature functions, some of which could be valuable to deal with xml formatting. A solution that deals with any formatting and task will be a outstanding choice when selecting software.
Get file management and generation to a different level of simplicity and sophistication without opting for an difficult program interface or high-priced subscription plan. DocHub offers you instruments and features to deal efficiently with all of file types, including xml, and carry out tasks of any complexity. Edit, arrange, and produce reusable fillable forms without effort. Get full freedom and flexibility to take out flag in xml anytime and safely store all of your complete documents within your account or one of several possible incorporated cloud storage apps.
DocHub offers loss-free editing, signature collection, and xml management on a expert level. You do not need to go through exhausting guides and spend hours and hours finding out the platform. Make top-tier safe file editing a standard process for the every day workflows.
hi this is Jeff Heaton you know Wikipedia is a massive amount of text that contains somewhat the sum total of human knowledge or at least at a very general level were going to see how to actually download and process the Wikipedia data at a very very low level literally pull the XML file across see what the structure looks like and this allows us to iterate through the whole thing potentially without using any sort of high capacity compute environment were going to simply stream through the whole thing and not load the entire thing into memory this can be useful for a couple of different operations now of course you can load it into SPARC and do these kind of things in seconds but this will still have relatively short processing time Ill show you how to do some things where we process through the entire of Wikipedia at about 20 minutes and not have to load the entire thing into RAM this provides the foundation for some natural language processing topics that I want to get into in t
