



Disadvantages exist in every tool for editing every document type, and despite the fact that you can find many tools on the market, not all of them will fit your particular requirements. DocHub makes it much simpler than ever to make and modify, and handle paperwork - and not just in PDF format.
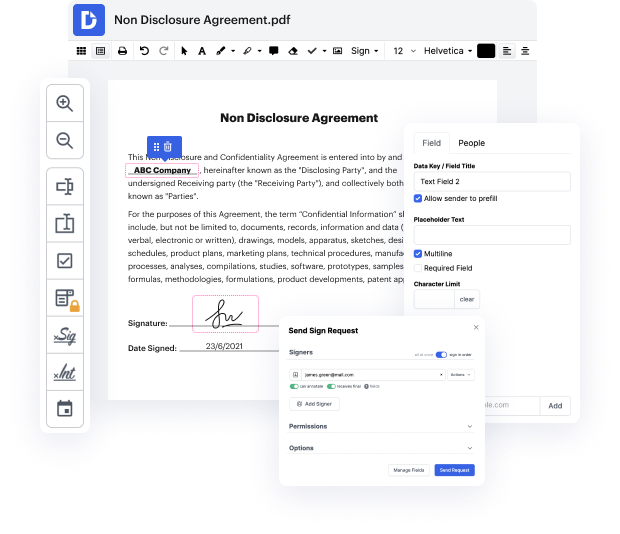
Every time you need to swiftly blot out portrait in HWPML, DocHub has got you covered. You can effortlessly modify form elements such as text and images, and structure. Customize, organize, and encrypt documents, develop eSignature workflows, make fillable documents for smooth data collection, and more. Our templates feature enables you to generate templates based on paperwork with which you frequently work.
Additionally, you can stay connected to your go-to productivity features and CRM platforms while handling your documents.
One of the most extraordinary things about using DocHub is the option to manage form activities of any difficulty, regardless of whether you need a swift edit or more complex editing. It includes an all-in-one form editor, website form builder, and workflow-centered features. Additionally, you can be certain that your paperwork will be legally binding and abide by all security frameworks.
Shave some time off your tasks with DocHub's tools that make managing documents straightforward.
good evening weamp;#39;re in group four uh Christopher Lee s ago Robert Martin Taylor TG and myself Michael Cruz will be presenting blit bootstrapping language image pre-training for unified Vision language understanding and generation so what was the motivation behind the blit model architecture previous VP models had many obstacles to overcome one of the most impaired was how to obtain large volumes of image text pairs one solution was using images accompanied by human annotated captions however this was very time and labor intensive and wasnamp;#39;t optimal to scale up BP models another option was to gather image text pairs on the internet via web scraping or other techniques but this introduced noisy textual data into the model because captions donamp;#39;t necessarily accurately represent the image theyamp;#39;re describing so this method also requires a lot of human intervention or remove noise from the data set to solve this problem the blit model introduces a noble cap fil
