



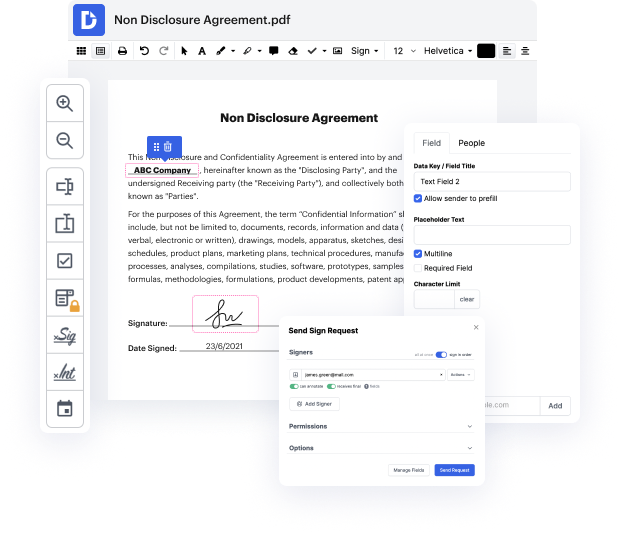
La gestión de archivos efectiva pasó de lo analógico a lo electrónico hace mucho tiempo. Llevarlo a un nivel más alto de efectividad solo requiere un acceso rápido a funciones de modificación que no dependen de qué dispositivo o navegador utilices. Si deseas Guardar PDF de Campo Avanzado en el Sitio Web, puedes hacerlo tan rápido como en cualquier otro dispositivo que tú o los miembros de tu equipo tengan. Puedes editar y crear archivos fácilmente siempre que conectes tu dispositivo a la web. Un conjunto de herramientas simple y una interfaz amigable son parte de la experiencia de DocHub.
DocHub es una solución potente para crear, modificar y compartir PDFs o cualquier otro documento y refinar tus procesos documentales. Puedes usarlo para Guardar PDF de Campo Avanzado en el Sitio Web, ya que solo necesitas tener una conexión a internet. Lo hemos diseñado para que funcione en cualquier sistema que las personas usen para trabajar, por lo que las preocupaciones de compatibilidad desaparecen cuando se trata de editar PDFs. Simplemente sigue estos pasos simples para Guardar PDF de Campo Avanzado en el Sitio Web en poco tiempo.
Nuestra compatibilidad con el software de modificación de PDF de calidad no depende de qué dispositivo emplees. Prueba nuestro editor universal de DocHub; nunca tendrás que preocuparte de si funcionará en tu dispositivo. Mejora tu proceso de edición simplemente registrando una cuenta.
En el tutorial de video de hoy, aprenderemos cómo extraer información de archivos PDF utilizando Python. El objetivo es utilizar diferentes bibliotecas para extraer tablas, imágenes y texto de los PDF. Mientras que una biblioteca puede ser capaz de extraer todos los tipos de datos, es más eficiente utilizar bibliotecas específicas para cada tarea. Cubriremos tres secciones diferentes en este tutorial, cada una utilizando un paquete de Python diferente para extraer tablas, imágenes y texto de archivos PDF. Este enfoque hará que el proceso de análisis de PDF sea más manejable.

En DocHub, la seguridad de tus datos es nuestra prioridad. Seguimos HIPAA, SOC2, GDPR y otros estándares, para que puedas trabajar en tus documentos con confianza.
Aprende más