



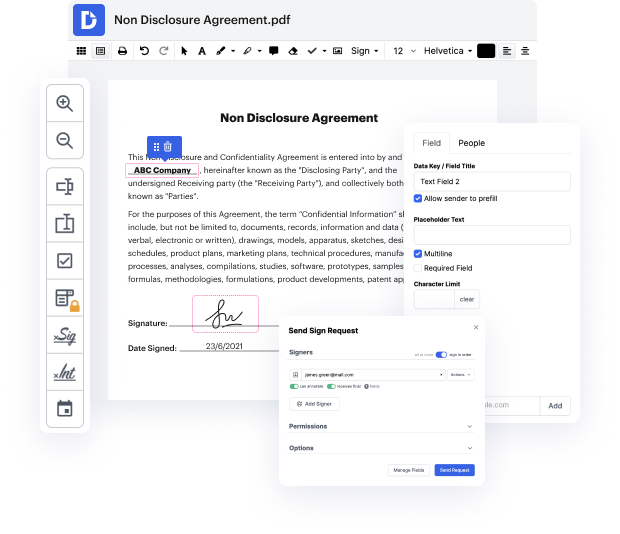
Trabajar con documentos como la Cotización de Traducción puede parecer un desafío, especialmente si estás trabajando con este tipo por primera vez. A veces, una pequeña modificación puede crear un gran dolor de cabeza cuando no sabes cómo manejar el formato y evitar hacer un caos del proceso. Cuando se te asigna vincular una imagen en la Cotización de Traducción, siempre puedes usar un software de modificación de imágenes. Otros pueden optar por un editor de texto clásico pero se quedan atascados cuando se les pide reformatear. Con DocHub, sin embargo, manejar una Cotización de Traducción no es más difícil que modificar un archivo en cualquier otro formato.
Prueba DocHub para una edición de documentos rápida y eficiente, independientemente del formato del documento que tengas en tus manos o del tipo de documento que necesites corregir. Esta solución de software es en línea, accesible desde cualquier navegador con una conexión a internet estable. Revisa tu Cotización de Traducción justo cuando la abras. Hemos diseñado la interfaz para asegurar que incluso los usuarios sin experiencia previa puedan hacer fácilmente todo lo que necesiten. Simplifica la edición de tus formularios con una única solución optimizada para cualquier tipo de documento.
Tratar con diferentes tipos de documentos no debe sentirse como ciencia espacial. Para optimizar tu tiempo de edición de documentos, necesitas una plataforma ágil como DocHub. Maneja más con todas nuestras herramientas a tu disposición.
el aprendizaje contrastivo ha visto un auge de interés en las técnicas de aprendizaje auto-supervisado, especialmente en visión por computadora, con artículos como simclr, moco y bootstrap your own latent. estos algoritmos de aprendizaje mapean representaciones de claves positivas para que sean similares y claves negativas para que sean disimilares. investigadores de uc berkeley y docHub research diseñaron un modelo que utiliza el aprendizaje contrastivo para el problema de traducción de imagen a imagen no emparejada, encajándolo en el modelo de red generativa adversarial. aquí es donde tenemos un conjunto de imágenes fuente, como caballos, y un conjunto de imágenes objetivo, como cebras, pero no están emparejadas explícitamente entre sí en el conjunto de entrenamiento. no hay una cebra correspondiente para cada imagen de caballo en el conjunto de datos fuente. los investigadores utilizan una comparación a nivel de parche, donde los parches en la imagen generada que son producidos por el generador deben ser similares al parche en la misma ubicación que en la imagen original y disimilares a todos los otros parches en esa misma imagen original.

En DocHub, la seguridad de tus datos es nuestra prioridad. Seguimos HIPAA, SOC2, GDPR y otros estándares, para que puedas trabajar en tus documentos con confianza.
Aprende más