



El mercado de gestión de documentos de hoy en día es enorme, por lo que encontrar la solución adecuada que satisfaga tus necesidades y tus expectativas de calidad-precio puede ser un proceso que consume tiempo y es engorroso. No hay necesidad de perder tiempo navegando por la web buscando un editor universal y fácil de usar para unirse a la vista en archivos ODM. DocHub está aquí para ayudarte siempre que lo necesites.
DocHub es un editor de documentos en línea reconocido a nivel mundial, confiado por millones. Puede satisfacer casi cualquier demanda de los usuarios y cumple con todos los requisitos de seguridad y cumplimiento necesarios para garantizar que tus datos estén bien protegidos mientras alteras tu archivo ODM. Considerando su potente e intuitiva interfaz ofrecida a un precio asequible, DocHub es una de las mejores opciones disponibles para una gestión de documentos optimizada.
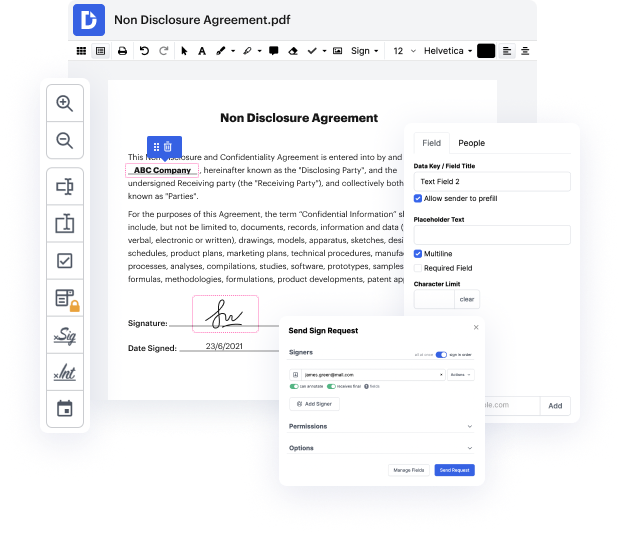
DocHub ofrece muchas otras características para una edición de formularios eficiente. Por ejemplo, puedes convertir tu formulario en una plantilla de uso múltiple después de editar o crear una plantilla desde cero. ¡Explora todas las capacidades de DocHub ahora!
¿Qué tal a todos? Gracias por unirse a mí nuevamente esta semana. Hoy vamos a hablar sobre las uniones por fusión. Este es el video número dos de una serie de tres partes sobre operadores de unión física y el servidor SQL. Enlazaré los otros videos de la serie a continuación a medida que salgan, así que vayan a verlos. Pero vamos a sumergirnos directamente en las uniones por fusión hoy. Las uniones por fusión son teóricamente el operador de unión física más rápido disponible para nosotros en el servidor SQL. La razón por la que son tan rápidas es que el servidor SQL solo tiene que iterar sobre cada fila en ambas entradas de nuestra unión por fusión una sola vez. No hay que retroceder y volver a recorrer las cosas como ocurriría en una unión por bucle anidado y en una unión hash. Sin embargo, la desventaja aquí es que solo obtienes esa velocidad en una unión por fusión porque las entradas necesitan estar ordenadas y esos datos entrantes están ordenados ya sea porque ya los tienes preordenados en algo como un índice o porque el servidor SQL decide que el costo es lo suficientemente bajo como para simplemente ordenar los datos.
