



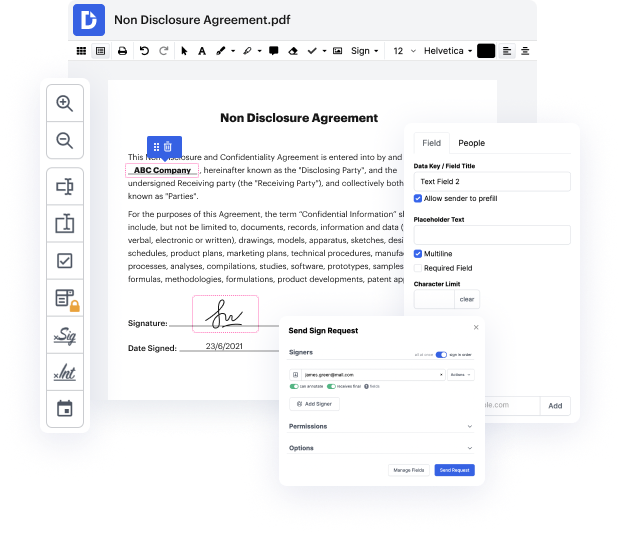
Tener control completo de tus archivos en cualquier momento es importante para aliviar tus tareas diarias y aumentar tu eficiencia. Logra cualquier objetivo con las herramientas de DocHub para la gestión de documentos y la edición práctica de archivos PDF. Obtén acceso, cambia y guarda e incorpora tus flujos de trabajo junto con otros servicios de almacenamiento en la nube seguros.
DocHub te ofrece edición sin pérdida, la oportunidad de trabajar con cualquier formato y firmar documentos de forma segura sin buscar una alternativa de firma electrónica de terceros. Obtén lo mejor de las soluciones de gestión de archivos en un solo lugar. Descubre todas las funciones de DocHub ahora con la cuenta gratuita.
¿Qué está pasando, chicos? Bienvenidos de nuevo. En el video de hoy vamos a aprender cómo extraer información de archivos PDF en Python, así que vamos a entrar en materia. [Música] Muy bien, al preparar el código para este video, quería encontrar una solución donde pudiera usar solo una simple biblioteca de Python para trabajar con archivos PDF, para extraer tablas, para extraer imágenes, para extraer texto, y así sucesivamente, todo con una simple biblioteca. Y aunque creo que es posible hacer todo esto con una de estas bibliotecas, descubrí que es mejor o más fácil usar diferentes bibliotecas para los diferentes casos de uso. Así que si quieres extraer imágenes, hay una biblioteca que lo hace fácil para ti; si quieres extraer texto, hay una biblioteca que lo hace fácil para ti; y si quieres extraer tablas, hay una biblioteca diferente que lo hace fácil para ti. Así que en el video de hoy vamos a hacer tres secciones donde usamos tres paquetes de Python diferentes para hacer tres cosas diferentes con archivos PDF. Si estás trabajando en un gran análisis de PDF.
