



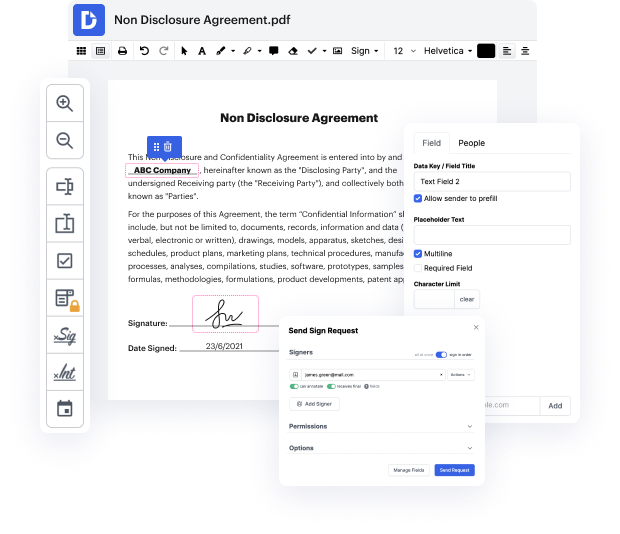
No todos los formatos, como xml, están desarrollados para ser fácilmente editados. A pesar de que muchas herramientas pueden ayudarnos a cambiar todos los formatos de formulario, nadie ha creado aún una herramienta real que sirva para todos los tamaños.
DocHub ofrece una herramienta sencilla y eficiente para editar, manejar y almacenar documentos en los formatos más populares. No tienes que ser un usuario con conocimientos tecnológicos para oscurecer etiquetas en xml o hacer otras modificaciones. DocHub es lo suficientemente potente como para hacer que el proceso sea sencillo para todos.
Nuestra herramienta te permite cambiar y ajustar documentos, enviar datos de un lado a otro, generar formularios dinámicos para la recopilación de información, cifrar y proteger documentos, y configurar flujos de trabajo de firma electrónica. Además, también puedes generar plantillas a partir de documentos que utilizas regularmente.
Encontrarás una gran cantidad de herramientas adicionales dentro de DocHub, incluidas integraciones que te permiten vincular tu formulario xml a varios programas de productividad.
DocHub es una forma sencilla y a un precio razonable de manejar documentos y agilizar flujos de trabajo. Ofrece una amplia gama de capacidades, desde la creación hasta la edición, soluciones de firma electrónica y creación de documentos web. La aplicación puede exportar tus archivos en múltiples formatos mientras mantiene la máxima seguridad y se adhiere a los criterios de seguridad de información más altos.
Pruébalo y descubre lo sencillo que puede ser tu proceso de edición.
hola, mi nombre es Manish Gupta y en este video voy a hablar sobre XML CNN que es básicamente un modelo de aprendizaje profundo para la clasificación de texto de múltiples etiquetas extremas, así que empecemos. La clasificación de texto de múltiples etiquetas extremas es el problema donde tienes como entrada un documento de texto y quieres clasificarlo en múltiples categorías o etiquetas posibles de un conjunto muy grande de etiquetas. Por ejemplo, dado una página de Wikipedia, quieres clasificarla en una de decenas de miles o probablemente cientos de miles de categorías posibles, ¿verdad? Así que las personas tradicionalmente no han estado usando modelos de aprendizaje profundo, han estado usando modelos basados en incrustaciones de etiquetas, modelos basados en árboles, clasificadores Uno contra Todos, y así sucesivamente. Pero esta fue la primera vez en cierto modo que estas personas intentaron usar modelos de aprendizaje profundo para este problema de clasificación de múltiples niveles extremos, específicamente para texto. El modelo es bastante simple, si lo piensas en el mundo de hoy, ellos ess
