



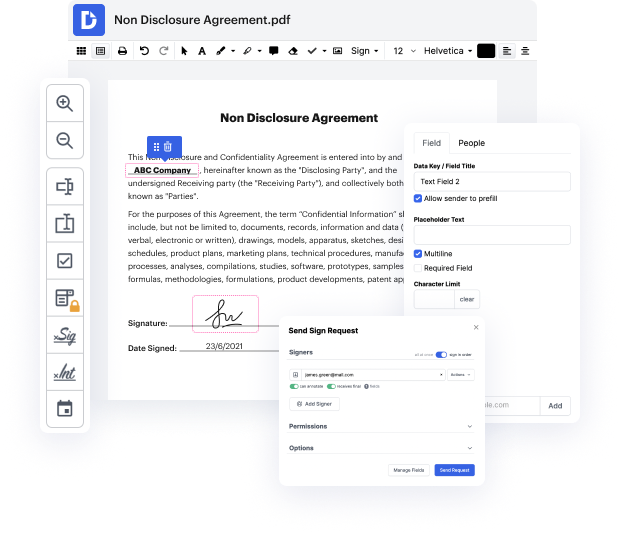
Hay tantas herramientas de edición de documentos en el mercado, pero solo unas pocas son compatibles con todos los tipos de archivos. Algunas herramientas son, por el contrario, versátiles pero difíciles de usar. DocHub proporciona la solución a estos problemas con su editor basado en la nube. Ofrece ricas funcionalidades que te permiten completar tus tareas de gestión de documentos de manera eficiente. Si necesitas corregir rápidamente el índice en NEIS, ¡DocHub es la opción ideal para ti!
Nuestro proceso es increíblemente sencillo: subes tu archivo NEIS a nuestro editor → se transforma instantáneamente en un formato editable → aplicas todos los ajustes necesarios y lo actualizas profesionalmente. Solo necesitas unos minutos para completar tu documentación.
Cuando se apliquen todas las modificaciones, puedes convertir tu documentación en una plantilla multiusos. Simplemente necesitas ir al Menú del lado izquierdo de nuestro editor y hacer clic en Acciones → Convertir en Plantilla. Encontrarás tu documentación almacenada en una carpeta separada en tu Tablero, ahorrándote tiempo la próxima vez que necesites la misma plantilla. ¡Prueba DocHub hoy!
Hoy vamos a ejecutar consultas SQL contra a una tabla que contiene diez MIL registros. {{ Risa maníaca }} {{ Llamada telefónica }} ¿Qué pasa? Estoy en medio de un video. ¿No me digas? ¿TODO en RAM? Bueno, está bien. Hoy vamos a ejecutar consultas SQL contra a una tabla que contiene un .. Cien .. MIL millones de registros. {{ Risa maníaca }} Pero no te preocupes. Al usar índices, podemos acelerar rápidamente las consultas para que no tengas que experimentar el fenómeno conocido como aburrimiento. Trabajaremos con una sola tabla llamada persona que contiene 100 MIL millones de personas generadas aleatoriamente. La primera fila es una clave primaria auto-generada llamada personid. Las otras columnas son firstname, lastname y birthday. Para crear esta tabla, generamos aleatoriamente nombres usando los 1000 nombres femeninos, masculinos y apellidos más populares en los Estados Unidos. No ponderamos los nombres por frecuencia al generar nuestra muestra aleatoria. Los conjuntos de datos y el código de Python utilizado para generar los nombres aleatorios están disponibles.
