



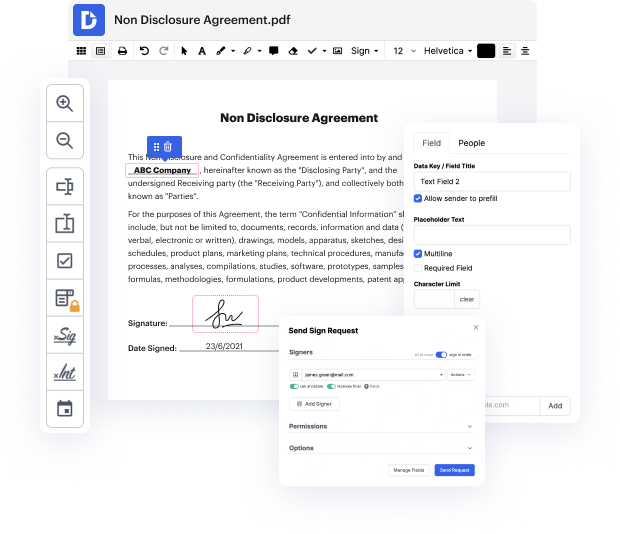
Cuando tratas con diferentes tipos de documentos como el Registro de Incidentes de Calidad, eres consciente de lo importante que son la precisión y la atención al detalle. Este tipo de documento tiene su propio formato particular, por lo que es crucial guardarlo con el formato intacto. Por esa razón, trabajar con este tipo de documentos puede ser un gran desafío para el software de edición de texto tradicional: una acción incorrecta puede desordenar el formato y llevar tiempo adicional para devolverlo a la normalidad.
Si deseas limpiar datos en el Registro de Incidentes de Calidad sin confusiones, DocHub es una herramienta perfecta para este tipo de tareas. Nuestra plataforma de edición en línea simplifica el proceso para cualquier acción que desees realizar con el Registro de Incidentes de Calidad. El diseño de interfaz elegante es adecuado para cualquier usuario, ya sea que esa persona esté acostumbrada a trabajar con este tipo de software o que solo lo haya abierto por primera vez. Accede rápidamente a todas las herramientas de edición que necesites y ahorra tiempo en las tareas diarias de edición. Todo lo que necesitas es una cuenta de DocHub.
Descubre lo sencillo que puede ser editar documentos sin importar el tipo de documento que tengas en tus manos. Accede a todas las funciones de edición de primera calidad y disfruta de la optimización de tu trabajo en documentos. Regístrate para obtener tu cuenta gratuita ahora y observa mejoras instantáneas en tu experiencia de edición.
hola queridos estudiantes, les doy la bienvenida a todos al curso de limpieza o depuración de datos en python este curso es muy importante desde la perspectiva de la ciencia de datos porque para construir sistemas automatizados inteligentes necesitamos tener datos de buena calidad la limpieza o depuración de datos es un paso de preprocesamiento que asegura que los datos que el modelo va a consumir para hacer predicciones sean válidos, precisos, consistentes y tengan uniformidad en sus valores si los datos no son de buena calidad no importa cuán mejor sea el modelo, los resultados no van a ser confiables los problemas comunes encontrados en datos recolectados de diferentes fuentes son valores faltantes, valores de ruido, valores atípicos, duplicación de registros, valores que están en diferentes escalas, características categóricas, etc. en este curso vamos a abordar estos problemas para convertir datos en bruto en datos de buena calidad que se pueden usar para construir modelos confiables que a su vez pueden producir buenos resultados de calidad en este curso vamos a discutir los diferentes conce...
