



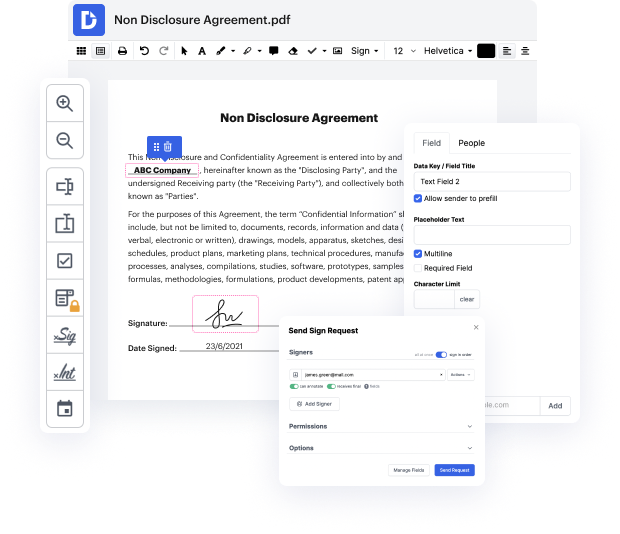
Tener control completo de tus documentos en cualquier momento es crucial para aliviar tus tareas diarias y mejorar tu eficiencia. Logra cualquier objetivo con las funciones de DocHub para la gestión de documentos y la edición conveniente de archivos PDF. Accede, ajusta, guarda e integra tus flujos de trabajo con otros servicios de almacenamiento en la nube seguros.
DocHub te ofrece edición sin pérdida, la posibilidad de usar cualquier formato y firmar documentos de forma segura sin buscar una opción de firma electrónica de terceros. Obtén lo mejor de las soluciones de gestión de archivos en un solo lugar. Descubre todas las capacidades de DocHub hoy con tu cuenta gratuita.
[Música] hola chicos bienvenidos a otro video de PI sound to talk mi nombre es J en este video voy a mostrarte cómo extraer texto de un archivo PDF usando Python así que bien, tienes un archivo PDF y este archivo PDF tiene algunas notas de clase que quiero extraer en un archivo de texto así que echemos un vistazo así que este archivo PDF tiene dos páginas y mi objetivo aquí es básicamente extraer todo el texto y guardarlo en un archivo de texto así que aquí abre tu editor de Python y crea un nuevo archivo de Python así que para imaginar el archivo PDF estaré usando la biblioteca pi-pdf2 y puedes instalar la biblioteca usando el comando pip install pi-pdf2 quiero importar una clase de lector de archivos PDF y una clase de escritor de archivos PDF así que primero necesitamos crear una variable para almacenar la ruta del archivo así que aquí obtenemos la ruta del archivo PDF y dado que mi archivo de Python y mi PDF están almacenados en la misma carpeta, así que puedo simplemente proporcionar directamente el nombre del archivo a continuación necesito abrir el archivo o usando la clase de lector de archivos PDF Ill
