



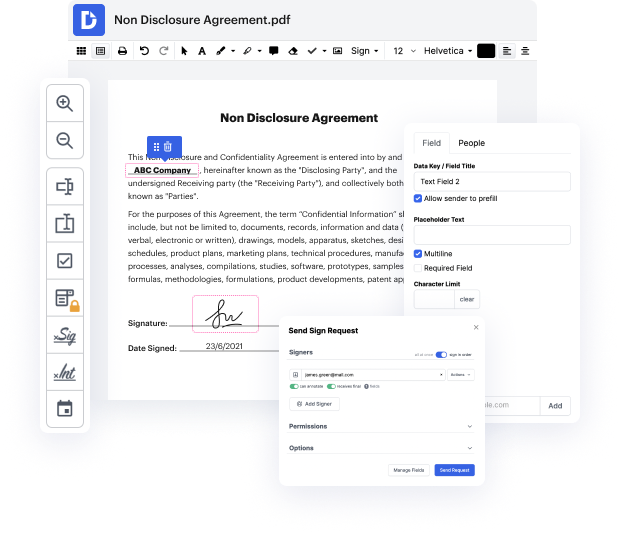
Muchas empresas pasan por alto los beneficios de una aplicación de flujo de trabajo completa. Por lo general, los programas de flujo de trabajo se centran en un solo elemento de generación de documentos. Hay mayores opciones para numerosos sectores que necesitan un enfoque adaptable a sus tareas, como la preparación de patentes. Sin embargo, es posible descubrir una opción holística y multifuncional que pueda atender todas tus necesidades y requisitos. Por ejemplo, DocHub es tu primera opción para flujos de trabajo simplificados, generación de documentos y aprobación.
Con DocHub, puedes crear documentos completamente desde cero utilizando una extensa lista de herramientas y características. Puedes limpiar rápidamente el texto en la patente, agregar comentarios y notas adhesivas, y rastrear el avance de tu documento de principio a fin. Rápidamente rota y reorganiza, y combina archivos PDF y trabaja con cualquier formato disponible. Olvídate de intentar encontrar plataformas de terceros para atender las demandas más básicas de generación de documentos y utiliza DocHub.
Toma el control total de tus formularios y documentos en cualquier momento y crea Plantillas de patente reutilizables para los documentos más utilizados. Aprovecha al máximo nuestras Plantillas para evitar cometer errores típicos al copiar y pegar exactamente la misma información y ahorra tiempo en esta tarea tediosa.
Optimiza todas tus operaciones de documentos con DocHub sin sudar. Descubre todas las oportunidades y características para la gestión de patentes hoy. Comienza tu perfil gratuito de DocHub hoy sin tarifas ocultas ni compromiso.
si alguna vez has oído la frase basura entra, basura sale al crear un modelo, lo mismo se aplica al análisis de texto. Acabamos de aprender cómo tokenizar, lo que realmente puede exponer la posible basura en nuestro texto. Demos el siguiente paso después de la tokenización y creemos un mejor texto de entrada para obtener un mejor análisis. Antes de ver algunos pasos simples de preprocesamiento para limpiar nuestros datos, me gustaría presentar un segundo conjunto de datos que estaremos explorando. 538 publicó recientemente una gran cantidad de datos públicos. Uno de estos conjuntos de datos consistió en casi tres millones de tweets de trolls rusos. Estos son tweets de bots que tuitearon durante el ciclo electoral de EE. UU. de 2016. Exploraremos los primeros 20,000 tweets, así como usar algunos de los metadatos, como el número de seguidores, el número de seguidos, la fecha de publicación y el tipo de cuenta, para ayudar en parte de nuestro análisis. Este es un gran conjunto de datos para modelado de temas, tareas de clasificación, reconocimiento de entidades nombradas y otros. Puedes imaginar que los tweets probablemente tienen mucha basura. Para mostrar esto, veamos los más comunes.
